Qué hace
El módulo de búsqueda de hash calcula los valores de hash MD5 para archivos y busca valores de hash en una base de datos para determinar si el archivo es notable, conocido (en general) o desconocido.
Configuración
La pestaña Conjuntos hash en el panel Opciones es donde puede configurar y actualizar la información de su conjunto hash. Los conjuntos de hash se utilizan para identificar archivos que son ‘conocidos’ o ‘notables’.
- Los archivos buenos conocidos son aquellos que pueden ignorarse con seguridad. Este conjunto de archivos con frecuencia incluye SO estándar y archivos de aplicación. Ignorar estos archivos poco interesantes para el investigador puede reducir en gran medida el tiempo de análisis de imágenes.
- Los archivos notables (o conocidos malos) son aquellos que deberían crear conciencia. Este conjunto variará según el tipo de investigación, pero los ejemplos comunes incluyen imágenes de contrabando y malware.
Importar conjuntos de hash
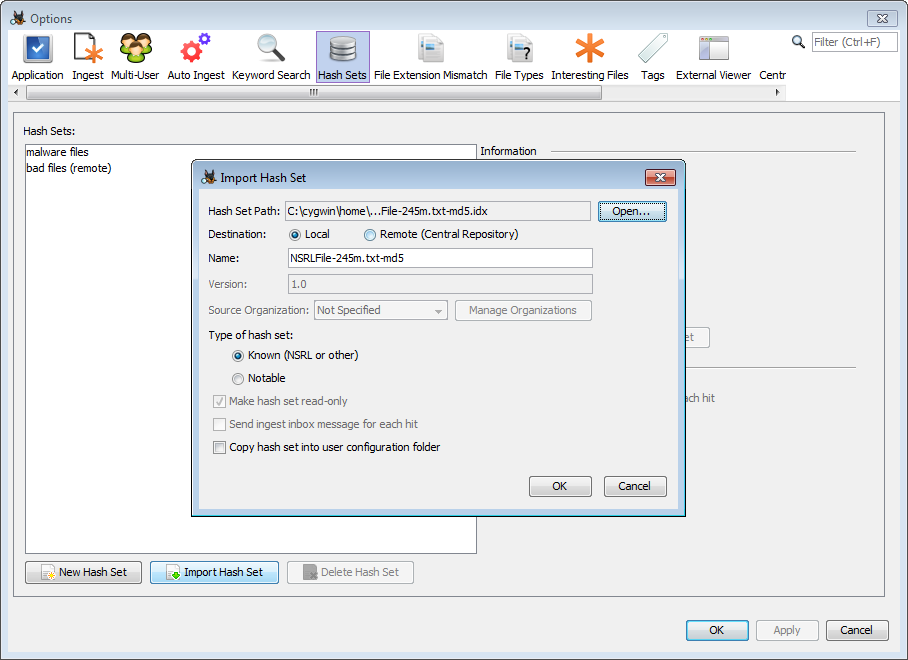
Para importar un conjunto de hash existente, use el botón «Importar base de datos» en el panel de opciones de conjuntos de hash. Aparecerá un cuadro de diálogo para importar el archivo.
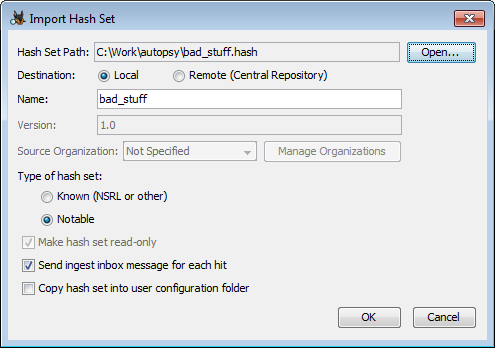
Ruta de la base de datos : la ruta al conjunto de hash que está importando. La autopsia admite los siguientes formatos:
- Texto: un hash que comienza cada línea. Por ejemplo, el resultado de ejecutar el programa md5, md5sum o md5deep en un conjunto de archivos (* .txt)
- Solo índice: generado por Sleuth Kit / Autopsy. El NSRL está disponible en este formato para usar con Autopsia ( ver más abajo ) (* .idx)
- Base de datos de Sleuth Kit / Autopsy format: conjuntos de hash de SQLite creados por Autopsy (* .kdb)
- EnCase: un archivo de conjunto de hash de EnCase (* .hash)
- HashKeeper: archivo de conjunto de hash conforme al estándar HashKeeper (* .hsh)
Destino : el campo Destino se refiere a dónde se almacenará el conjunto de hash.
- Local: el archivo de conjunto de hash se usará desde la ubicación original en el disco
- Remoto: el conjunto de hash se copiará en el repositorio central . Cuando se utiliza un repositorio central de PostgreSQL, esto permite que varios usuarios compartan fácilmente los mismos conjuntos de hash.
Nombre : muestra el nombre del conjunto de hash. Se sugerirá uno en función del nombre del archivo, pero esto se puede cambiar.
Versión : la versión del conjunto de hash solo se puede ingresar al importar el conjunto de hash en el repositorio central. Además, no se puede ingresar ninguna versión si el conjunto de hash no es de solo lectura.
Organización de origen : la organización solo se puede ingresar al importar el conjunto de hash en el repositorio central. Consulte la sección sobre gestión de organizaciones para obtener más información.
Tipo de base de datos : todas las entradas en el conjunto de hash deben ser «conocidas» (pueden ignorarse de forma segura) o «notables» (podrían ser indicadores de comportamiento sospechoso).
Hacer que la base de datos sea de solo lectura: la configuración de solo lectura solo está activa cuando se importa el conjunto hash en el repositorio central. Una base de datos de solo lectura no puede tener nuevos hashes agregados a través del panel de opciones Hash Sets o el menú contextual. Para los conjuntos de hash importados localmente, si se puede escribir en ellos depende del tipo de conjunto de hash. Las bases de datos en formato de autopsia (* .kdb) se pueden editar, pero todos los demás tipos serán de solo lectura.
Enviar mensaje de bandeja de entrada de entrada para cada hit : determina si se envía un mensaje para cada archivo coincidente. Esto no se puede habilitar para un conjunto de hash «conocido».
Copiar conjunto hash en la carpeta de configuración del usuario : realiza una copia del conjunto hash en lugar de utilizar el existente. Esto está destinado a ser utilizado con la creación de una unidad de disco de triaje en vivo .
Indexación
Después de importar el conjunto de hash, es posible que deba indexarlo antes de poder usarlo. Para la mayoría de los tipos de conjuntos de hash, Autopsy necesita un índice del conjunto de hash para usar realmente un conjunto de hash. Puede crear el índice si importa solo el conjunto de hash. Cualquier conjunto de hash que requiera un índice se mostrará en rojo, y su «Estado del índice» indicará que es necesario crear un índice. Esto se hace simplemente usando el botón Índice.
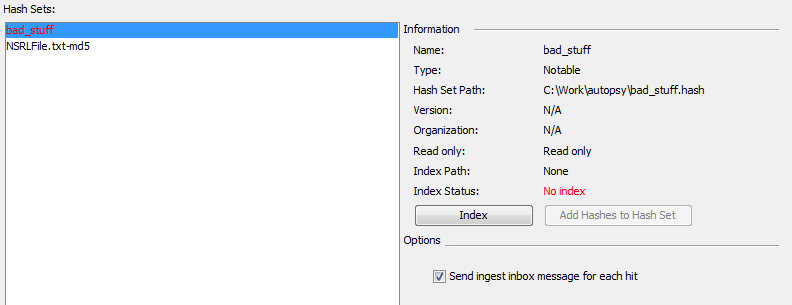
Autopsy utiliza el sistema de gestión de conjuntos hash de The Sleuth Kit. Puede crear manualmente un índice con la herramienta de línea de comandos ‘hfind’ o puede usar Autopsia. Si intenta continuar sin indexar un conjunto de hash, Autopsy le ofrecerá producir automáticamente un índice para usted. También puede especificar solo el archivo de índice y no usar el conjunto de hash completo; el archivo de índice es suficiente para identificar los archivos conocidos. Esto puede ahorrar espacio. Para hacer esto, especifique el archivo .idx desde el panel de opciones Hash Sets.
Crear conjuntos de hash
Se pueden crear nuevos conjuntos de hash utilizando el botón «Nuevo conjunto de hash». Los campos son en su mayoría iguales al cuadro de diálogo de importación descrito anteriormente.
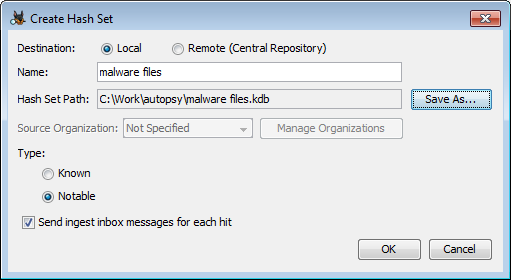
En este caso, la ruta de la base de datos es donde se almacenará la nueva base de datos. Si se está utilizando el repositorio central, entonces este campo no es necesario.
Usar conjuntos de hash
Hay un módulo de ingesta que hará un hash de los archivos y los buscará en los conjuntos de hash. Marcará los archivos que se encontraban en el conjunto de hash notable y esos resultados se mostrarán en el árbol Resultados del Visor de árboles . Otros módulos de ingesta pueden usar el estado conocido de un archivo para decidir si deben ignorar el archivo o procesarlo. También puede ver los resultados en la ventana Búsqueda de archivos . Hay una opción para elegir el «estado conocido». Desde aquí, puede hacer una búsqueda para ver todos los archivos ‘notables’. Desde aquí, también puede optar por ignorar todos los archivos ‘conocidos’ que se encontraron en el NSRL. También puede ver el estado del archivo en una columna cuando el archivo aparece en la lista.
NIST NSRL
La autopsia puede usar el NIST NSRL para detectar ‘archivos conocidos’. El NSRL contiene hashes de ‘archivos conocidos’ que pueden ser buenos o malos dependiendo de su perspectiva y tipo de investigación. Por ejemplo, la existencia de una pieza de software financiero puede ser interesante para su investigación y ese software podría estar en el NSRL. Por lo tanto, Autopsy trata los archivos que se encuentran en el NSRL simplemente como ‘conocidos’ y no especifica buenos o malos. Los módulos de ingesta tienen la opción de ignorar los archivos que se encontraron en el NSRL.
Para usar el NSRL, puede descargar un índice prefabricado de http://sourceforge.net/projects/autopsy/files/NSRL . Descargue NSRL-XYZm-autopsy.zip (donde ‘XYZ’ es el número de versión. Al momento de escribir esto, es 247) y descomprima el archivo. Use el menú «Herramientas», «Opciones» y seleccione la pestaña «Conjuntos de hash». Haga clic en «Importar base de datos» y busque la ubicación del archivo NSRL descomprimido. Puede cambiar el nombre del conjunto de hash si lo desea. Seleccione el tipo de base de datos que desee, elija «Enviar mensaje de entrada de la bandeja de entrada para cada hit» si lo desea, y luego haga clic en «Aceptar».
Usando el Módulo
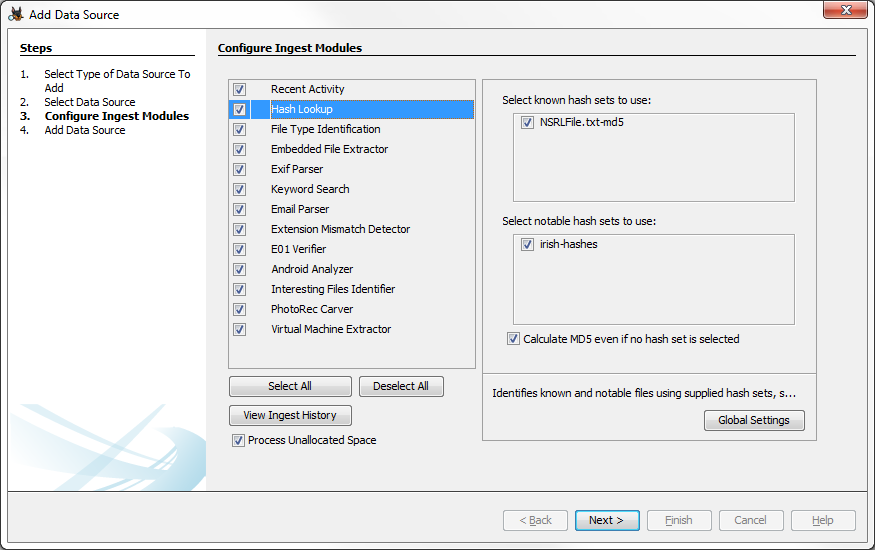
Configuración de ingesta
Cuando se configuran los conjuntos de hash, el usuario puede seleccionar los conjuntos de hash para usar durante el proceso de ingesta.
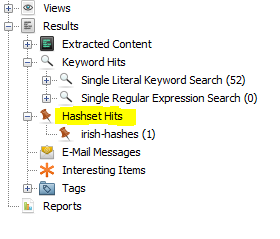
Viendo resultados
Los resultados se muestran en el árbol como «Hashset Hits», agrupados por el nombre del conjunto de hash.